
突发!腾讯AI Lab撤销,部分人员并入混元
突发!腾讯AI Lab撤销,部分人员并入混元今天,机器之心获悉,腾讯 TEG 技术工程事业群组织架构发生了部分调整,AI Lab 被撤销,蒋杰不再担任 AI Lab 主任,但其他管理职责不变。此次调整过后,原 AI Lab 部分人员调整至混元团队向姚顺雨汇报。产学研合作中心保留。多模态部负责人向 TEG 总裁卢山汇报。
来自主题: AI资讯
8976 点击 2026-03-21 09:32
 搜索
搜索
今天,机器之心获悉,腾讯 TEG 技术工程事业群组织架构发生了部分调整,AI Lab 被撤销,蒋杰不再担任 AI Lab 主任,但其他管理职责不变。此次调整过后,原 AI Lab 部分人员调整至混元团队向姚顺雨汇报。产学研合作中心保留。多模态部负责人向 TEG 总裁卢山汇报。
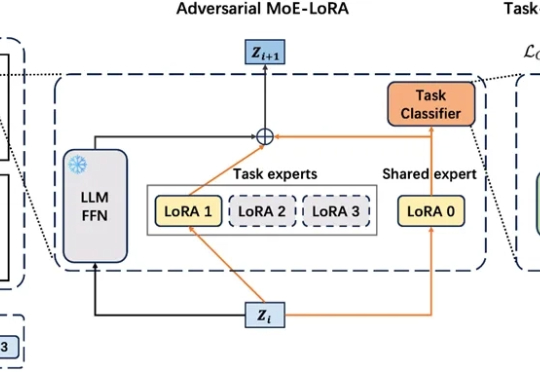
在工业级大语言模型(LLM)应用中,动态适配任务与保留既有能力的 “自进化” 需求日益迫切。真实场景中,不同领域语言模式差异显著,LLM 需在学习新场景合规规则的同时,不丢失旧场景的判断能力。这正是大模型自进化核心诉求,即 “自主优化跨任务知识整合,适应动态环境而无需大量外部干预”。
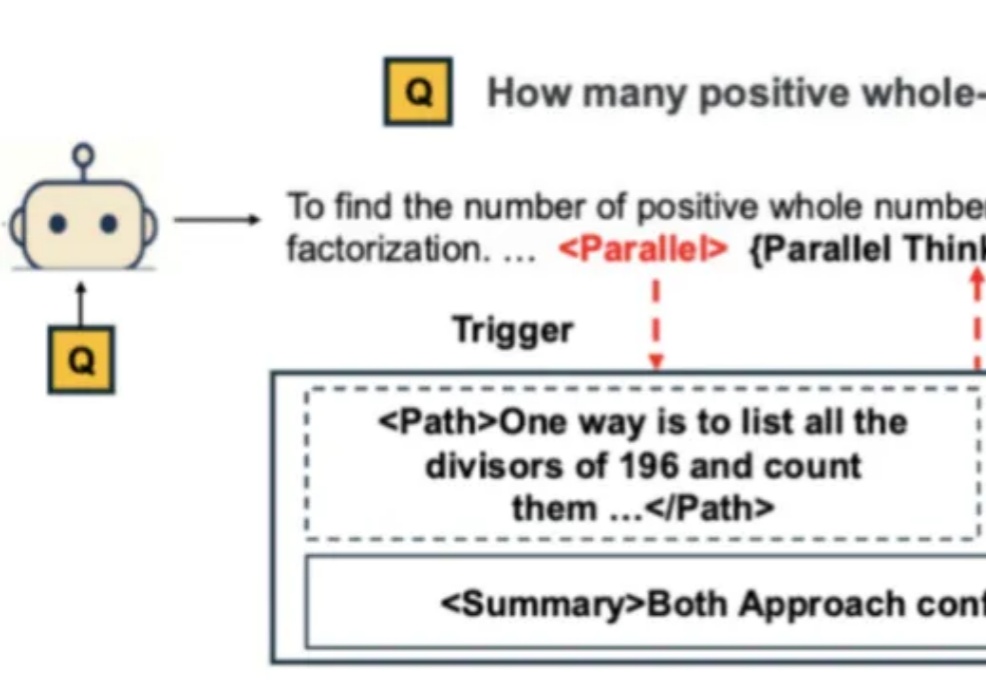
自从 Google Gemini 将数学奥赛的成功部分归功于「并行思维」后,如何让大模型掌握这种并行探索多种推理路径的能力,成为了学界关注的焦点。
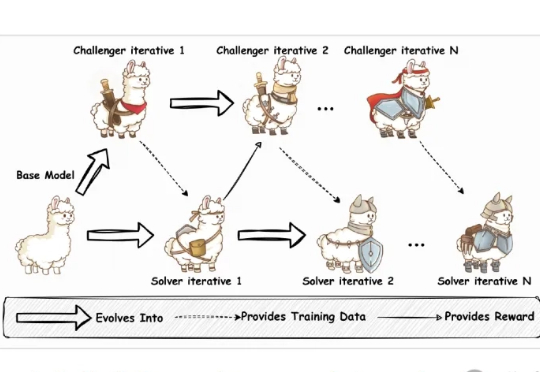
当前训练强大的大语言模型(LLM),就像是培养一个顶尖运动员,需要大量的、由专家(人类标注员)精心设计的训练计划和教材(高质量的标注数据)。
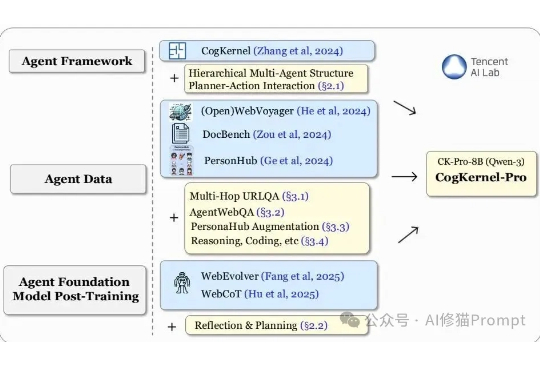
当AI智能体(Agent)开发的浪潮涌来,很多一线工程师却发现自己站在一个尴尬的十字路口:左边是谷歌、OpenAI等巨头深不可测的“技术黑盒”,右边是看似开放却暗藏“付费墙”的开源社区。大家空有场景和想法,却缺少一把能打开未来的钥匙。
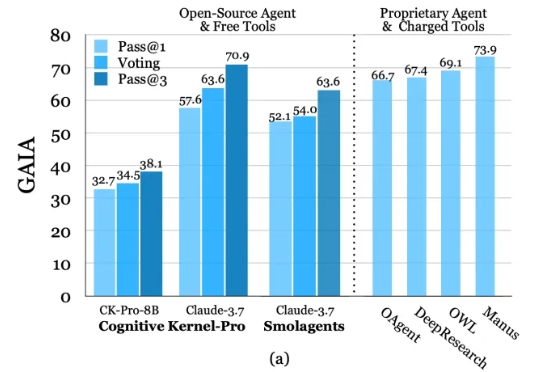
深度研究智能体(Deep Research Agents)凭借大语言模型(LLM)和视觉-语言模型(VLM)的强大能力,正在重塑知识发现与问题解决的范式。

据申妈朋友圈报道,原阿里通义千问语音团队负责人、前腾讯AI Lab副主任鄢志杰,已于近期正式加盟京东探索研究院
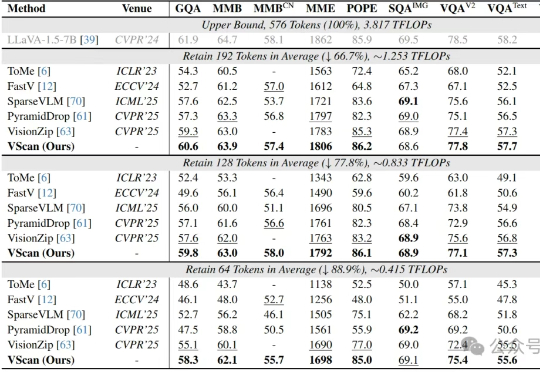
多图像、长视频、细粒度感知正在让大型视觉语言模型(LVLM)变得越来越聪明,但也越来越“吃不消”:视觉Token数量的激增所带来的推理成本暴涨,正逐渐成为多模态智能扩展的最大算力瓶颈。
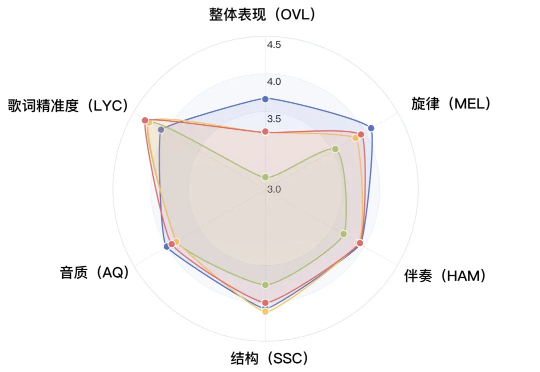
6 月 16 日,腾讯 AI Lab 推出并开源 SongGeneration 音乐生成大模型,专注解决音乐 AIGC 中音质、音乐性与生成速度这三大共性难题
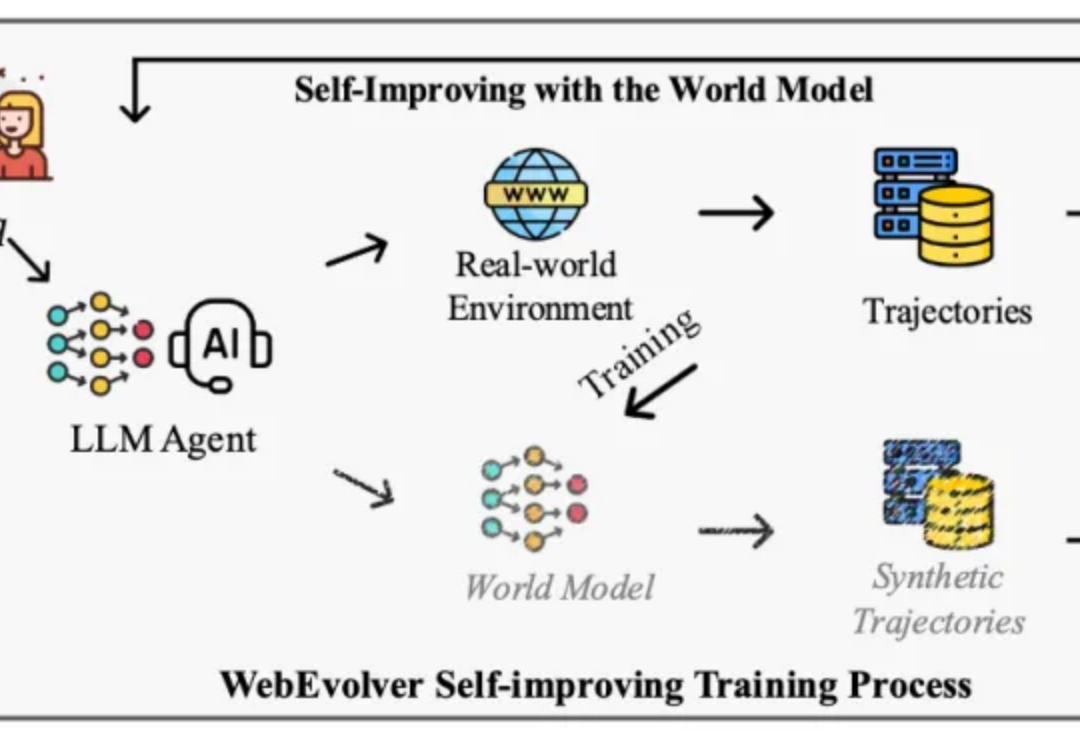
让网页智能体自演进突破性能天花板!